
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 텐서플로우
- machinelearning
- 컴퓨터비전
- 케라스
- 빅분기
- resnet
- Keras
- AI
- mnist
- 통계
- 데이터분석가
- 빅데이터분석기사
- 의학통계
- 코딩테스트
- TensorFlow
- 데이터전처리
- ComputerVision
- 의학논문
- 딥러닝
- 인공지능
- 파이썬
- 빅분기실기
- Python
- Deeplearning
- 데이터사이언스
- 머신러닝
- 데이터모델링
- CNN
- 데이터EDA
- 데이터분석
- Today
- Total
Be Brave, Be Humble
03_Fashion_MNIST_callbacks 본문

https://github.com/FulISun/Computer_Vision/blob/main/CNN/03_Fashion_MNIST_callbacks.ipynb
Fashion MNIST Example
- 정확도가 잘 안나오면 하이퍼 파라미터 먼저 수정하기~
learning rate -> epoch -> architecture 순으로 수정할 것
- accuracy는 그대로인데 loss만 감소하는 경우는 맞추는 값만 맞추고 틀린 값은 계속 틀려서 => decision making 필요함. 데이터 확인해서 코딩 오류 수정하거나 해당 값 삭제 해야함
ex) 정답 = [ 1, 2, 3, 4 ]
예측1 = [ 1, 2, 3, 3 ]
예측2 = [ 1, 2, 3, 10 ]
인 경우 둘 다 정확도는 0.75지만 loss가 예측2의 loss가 더 큼[1] Data 생성 및 확인
In [ ]:
import tensorflow as tf
import numpy as np
from tensorflow.keras.datasets import fashion_mnist
(x_train, t_train), (x_test, t_test) = fashion_mnist.load_data()
print('\n train shape = ', x_train.shape, ', train label shape = ', t_train.shape)
print(' test shape = ', x_test.shape, ', test label shape =', t_test.shape)
print('\n train label = ', t_train) # 학습데이터 정답 출력
print(' test label = ', t_test) # 테스트 데이터 정답 출력
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz
32768/29515 [=================================] - 0s 0us/step
40960/29515 [=========================================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz
26427392/26421880 [==============================] - 0s 0us/step
26435584/26421880 [==============================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz
16384/5148 [===============================================================================================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz
4423680/4422102 [==============================] - 0s 0us/step
4431872/4422102 [==============================] - 0s 0us/step
train shape = (60000, 28, 28) , train label shape = (60000,)
test shape = (10000, 28, 28) , test label shape = (10000,)
train label = [9 0 0 ... 3 0 5]
test label = [9 2 1 ... 8 1 5]
In [ ]:
import matplotlib.pyplot as plt
# 25개의 이미지 출력
plt.figure(figsize=(6, 6))
for index in range(25): # 25 개 이미지 출력
plt.subplot(5, 5, index + 1) # 5행 5열
plt.imshow(x_train[index], cmap='gray')
plt.axis('off')
plt.tight_layout()
plt.show()

In [ ]:
plt.imshow(x_train[9].reshape(28,28), cmap='gray')
plt.colorbar()
plt.show()
[2] 데이터 전처리
In [ ]:
# 학습 데이터 / 테스트 데이터 정규화 (Normalization)
x_train = (x_train - 0.0) / (255.0 - 0.0)
x_test = (x_test - 0.0) / (255.0 - 0.0)
[3] 모델 구축 및 컴파일
In [ ]:
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28, 28)))
model.add(tf.keras.layers.Dense(100, activation='relu'))
model.add(tf.keras.layers.Dense(10, activation='softmax'))
In [ ]:
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=1e-4),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.summary()
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_2 (Flatten) (None, 784) 0
dense_4 (Dense) (None, 100) 78500
dense_5 (Dense) (None, 10) 1010
=================================================================
Total params: 79,510
Trainable params: 79,510
Non-trainable params: 0
_________________________________________________________________
In [ ]:
from tensorflow.keras.optimizers import SGD
model.compile(optimizer=SGD(learning_rate=0.1),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.summary()
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_2 (Flatten) (None, 784) 0
dense_4 (Dense) (None, 100) 78500
dense_5 (Dense) (None, 10) 1010
=================================================================
Total params: 79,510
Trainable params: 79,510
Non-trainable params: 0
_________________________________________________________________
[4] 모델 학습 & Callback
- Callback 함수는 초기 모델에는 사용하지 말 것. 하이퍼 파라미터랑 모델 아키텍처랑 여러번 수정해본 후 수행할 것.
ReduceLROnPlateau
- 모델의 성능 개선이 없을 경우, Learning Rate를 조절해 모델의 개선을 유도하는 콜백함수. factor 파라미터를 통해서 학습율을 조정함 (factor < 1.0)
In [ ]:
from tensorflow.keras.callbacks import ReduceLROnPlateau
reduceLR = ReduceLROnPlateau(monitor = 'val_loss', # val_loss 기준으로 callback 호출
factor = 0.5, # callback 호출시 학습률을 1/2로 줄임
patience = 5, # epoch 5 동안 개선되지 않으면 callback 호출
verbose = 1) # 로그 출력
In [ ]:
hist = model.fit(x_train, t_train,
epochs = 50, validation_split = 0.2,
callbacks = [reduceLR])
Epoch 1/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2691 - accuracy: 0.9040 - val_loss: 0.3297 - val_accuracy: 0.8836 - lr: 1.0000e-04
Epoch 2/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2660 - accuracy: 0.9054 - val_loss: 0.3274 - val_accuracy: 0.8831 - lr: 1.0000e-04
Epoch 3/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2645 - accuracy: 0.9052 - val_loss: 0.3270 - val_accuracy: 0.8832 - lr: 1.0000e-04
Epoch 4/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2620 - accuracy: 0.9067 - val_loss: 0.3239 - val_accuracy: 0.8860 - lr: 1.0000e-04
Epoch 5/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2599 - accuracy: 0.9070 - val_loss: 0.3256 - val_accuracy: 0.8852 - lr: 1.0000e-04
Epoch 6/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.2573 - accuracy: 0.9089 - val_loss: 0.3249 - val_accuracy: 0.8850 - lr: 1.0000e-04
Epoch 7/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2563 - accuracy: 0.9081 - val_loss: 0.3247 - val_accuracy: 0.8857 - lr: 1.0000e-04
Epoch 8/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2532 - accuracy: 0.9094 - val_loss: 0.3220 - val_accuracy: 0.8838 - lr: 1.0000e-04
Epoch 9/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2511 - accuracy: 0.9100 - val_loss: 0.3316 - val_accuracy: 0.8824 - lr: 1.0000e-04
Epoch 10/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2495 - accuracy: 0.9129 - val_loss: 0.3216 - val_accuracy: 0.8867 - lr: 1.0000e-04
Epoch 11/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2471 - accuracy: 0.9120 - val_loss: 0.3204 - val_accuracy: 0.8862 - lr: 1.0000e-04
Epoch 12/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.2453 - accuracy: 0.9132 - val_loss: 0.3253 - val_accuracy: 0.8848 - lr: 1.0000e-04
Epoch 13/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2440 - accuracy: 0.9129 - val_loss: 0.3240 - val_accuracy: 0.8856 - lr: 1.0000e-04
Epoch 14/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2414 - accuracy: 0.9146 - val_loss: 0.3311 - val_accuracy: 0.8822 - lr: 1.0000e-04
Epoch 15/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2398 - accuracy: 0.9149 - val_loss: 0.3245 - val_accuracy: 0.8867 - lr: 1.0000e-04
Epoch 16/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2381 - accuracy: 0.9152 - val_loss: 0.3184 - val_accuracy: 0.8880 - lr: 1.0000e-04
Epoch 17/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2363 - accuracy: 0.9159 - val_loss: 0.3213 - val_accuracy: 0.8850 - lr: 1.0000e-04
Epoch 18/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2343 - accuracy: 0.9164 - val_loss: 0.3228 - val_accuracy: 0.8860 - lr: 1.0000e-04
Epoch 19/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2331 - accuracy: 0.9175 - val_loss: 0.3167 - val_accuracy: 0.8884 - lr: 1.0000e-04
Epoch 20/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2308 - accuracy: 0.9184 - val_loss: 0.3182 - val_accuracy: 0.8873 - lr: 1.0000e-04
Epoch 21/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2294 - accuracy: 0.9180 - val_loss: 0.3212 - val_accuracy: 0.8847 - lr: 1.0000e-04
Epoch 22/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2280 - accuracy: 0.9195 - val_loss: 0.3218 - val_accuracy: 0.8876 - lr: 1.0000e-04
Epoch 23/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.2258 - accuracy: 0.9199 - val_loss: 0.3217 - val_accuracy: 0.8865 - lr: 1.0000e-04
Epoch 24/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2242 - accuracy: 0.9198 - val_loss: 0.3165 - val_accuracy: 0.8872 - lr: 1.0000e-04
Epoch 25/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2225 - accuracy: 0.9209 - val_loss: 0.3161 - val_accuracy: 0.8888 - lr: 1.0000e-04
Epoch 26/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2208 - accuracy: 0.9215 - val_loss: 0.3209 - val_accuracy: 0.8880 - lr: 1.0000e-04
Epoch 27/50
1500/1500 [==============================] - 5s 3ms/step - loss: 0.2196 - accuracy: 0.9224 - val_loss: 0.3167 - val_accuracy: 0.8866 - lr: 1.0000e-04
Epoch 28/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2177 - accuracy: 0.9232 - val_loss: 0.3235 - val_accuracy: 0.8856 - lr: 1.0000e-04
Epoch 29/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2166 - accuracy: 0.9228 - val_loss: 0.3298 - val_accuracy: 0.8829 - lr: 1.0000e-04
Epoch 30/50
1493/1500 [============================>.] - ETA: 0s - loss: 0.2155 - accuracy: 0.9231
Epoch 30: ReduceLROnPlateau reducing learning rate to 4.999999873689376e-05.
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2154 - accuracy: 0.9232 - val_loss: 0.3188 - val_accuracy: 0.8884 - lr: 1.0000e-04
Epoch 31/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2089 - accuracy: 0.9267 - val_loss: 0.3154 - val_accuracy: 0.8889 - lr: 5.0000e-05
Epoch 32/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2081 - accuracy: 0.9269 - val_loss: 0.3181 - val_accuracy: 0.8866 - lr: 5.0000e-05
Epoch 33/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2072 - accuracy: 0.9281 - val_loss: 0.3167 - val_accuracy: 0.8872 - lr: 5.0000e-05
Epoch 34/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2064 - accuracy: 0.9277 - val_loss: 0.3160 - val_accuracy: 0.8893 - lr: 5.0000e-05
Epoch 35/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.2057 - accuracy: 0.9282 - val_loss: 0.3148 - val_accuracy: 0.8889 - lr: 5.0000e-05
Epoch 36/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2052 - accuracy: 0.9291 - val_loss: 0.3256 - val_accuracy: 0.8858 - lr: 5.0000e-05
Epoch 37/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.2042 - accuracy: 0.9285 - val_loss: 0.3166 - val_accuracy: 0.8884 - lr: 5.0000e-05
Epoch 38/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2035 - accuracy: 0.9290 - val_loss: 0.3185 - val_accuracy: 0.8867 - lr: 5.0000e-05
Epoch 39/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2029 - accuracy: 0.9287 - val_loss: 0.3162 - val_accuracy: 0.8885 - lr: 5.0000e-05
Epoch 40/50
1497/1500 [============================>.] - ETA: 0s - loss: 0.2019 - accuracy: 0.9295
Epoch 40: ReduceLROnPlateau reducing learning rate to 2.499999936844688e-05.
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2019 - accuracy: 0.9295 - val_loss: 0.3199 - val_accuracy: 0.8873 - lr: 5.0000e-05
Epoch 41/50
1500/1500 [==============================] - 5s 3ms/step - loss: 0.1988 - accuracy: 0.9315 - val_loss: 0.3152 - val_accuracy: 0.8880 - lr: 2.5000e-05
Epoch 42/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.1980 - accuracy: 0.9313 - val_loss: 0.3140 - val_accuracy: 0.8907 - lr: 2.5000e-05
Epoch 43/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.1981 - accuracy: 0.9311 - val_loss: 0.3148 - val_accuracy: 0.8892 - lr: 2.5000e-05
Epoch 44/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.1977 - accuracy: 0.9311 - val_loss: 0.3146 - val_accuracy: 0.8887 - lr: 2.5000e-05
Epoch 45/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.1969 - accuracy: 0.9313 - val_loss: 0.3158 - val_accuracy: 0.8898 - lr: 2.5000e-05
Epoch 46/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.1965 - accuracy: 0.9321 - val_loss: 0.3152 - val_accuracy: 0.8882 - lr: 2.5000e-05
Epoch 47/50
1480/1500 [============================>.] - ETA: 0s - loss: 0.1961 - accuracy: 0.9319
Epoch 47: ReduceLROnPlateau reducing learning rate to 1.249999968422344e-05.
1500/1500 [==============================] - 4s 3ms/step - loss: 0.1963 - accuracy: 0.9320 - val_loss: 0.3147 - val_accuracy: 0.8907 - lr: 2.5000e-05
Epoch 48/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.1948 - accuracy: 0.9325 - val_loss: 0.3143 - val_accuracy: 0.8879 - lr: 1.2500e-05
Epoch 49/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.1944 - accuracy: 0.9330 - val_loss: 0.3140 - val_accuracy: 0.8898 - lr: 1.2500e-05
Epoch 50/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.1940 - accuracy: 0.9335 - val_loss: 0.3143 - val_accuracy: 0.8892 - lr: 1.2500e-05
ModelCheckpoint
- 모델이 학습하면서 정의한 조건을 만족했을 때 model의 weigth값을 중간 저장함
- 학습시간이 오래 걸린다몀델이 개선된 validation score를 도출해낼 때마다 weight를 불러와서 중간 저장함으로써, 혹시 중간에 memory overflow나 crash가 나더라도 다시 weight를 불러와서 학습을 이어나갈 수 있기 때문에, 시간을 save 함
In [ ]:
from tensorflow.keras.callbacks import ModelCheckpoint
file_path = './modelcheckpoint_test.h5' # 저장할 파일 패스
checkpoint = ModelCheckpoint(file_path, # 저장할 파일 패스
moniter = 'val_loss', # val_loss 값이 개선되었을 때 호출
verbose = 1, # log 출력
save_best_only = True, # bset 값만 저장
model = 'auto') # auto는 자동으로 best 찾음
hist = model.fit(x_train, t_train, epochs=30, validation_split=0.2, callbacks = [checkpoint])
Epoch 1/30
1490/1500 [============================>.] - ETA: 0s - loss: 0.7852 - accuracy: 0.7457---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
<ipython-input-7-040846486389> in <module>()
9 model = 'auto') # auto는 자동으로 best 찾음
10
---> 11 hist = model.fit(x_train, t_train, epochs=30, validation_split=0.2, callbacks = [checkpoint])
/usr/local/lib/python3.7/dist-packages/keras/utils/traceback_utils.py in error_handler(*args, **kwargs)
62 filtered_tb = None
63 try:
---> 64 return fn(*args, **kwargs)
65 except Exception as e: # pylint: disable=broad-except
66 filtered_tb = _process_traceback_frames(e.__traceback__)
/usr/local/lib/python3.7/dist-packages/keras/engine/training.py in fit(self, x, y, batch_size, epochs, verbose, callbacks, validation_split, validation_data, shuffle, class_weight, sample_weight, initial_epoch, steps_per_epoch, validation_steps, validation_batch_size, validation_freq, max_queue_size, workers, use_multiprocessing)
1429 use_multiprocessing=use_multiprocessing,
1430 return_dict=True,
-> 1431 _use_cached_eval_dataset=True)
1432 val_logs = {'val_' + name: val for name, val in val_logs.items()}
1433 epoch_logs.update(val_logs)
/usr/local/lib/python3.7/dist-packages/keras/utils/traceback_utils.py in error_handler(*args, **kwargs)
62 filtered_tb = None
63 try:
---> 64 return fn(*args, **kwargs)
65 except Exception as e: # pylint: disable=broad-except
66 filtered_tb = _process_traceback_frames(e.__traceback__)
KeyboardInterrupt: EarlyStopping
- 모델 성능 지표가 설정한 epoch 동안 개선되지 않을 때 조기 종료
- 일반적으로 EalryStopping과 ModelCheckpoint 조합을 통하여, 개선되지 않는 학습에 대한 조기종료를 실행하고, ModelCheckpoint로부터 가장 best model을 다시 로드하여 학습을 재게할 수 있음
In [ ]:
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
file_path = './modelcheckpoint_test.h5' # 저장할 파일 패스
checkpoint = ModelCheckpoint(file_path, # 저장할 파일 패스
moniter = 'val_loss', # val_loss 값이 개선되었을 때 호출
verbose = 1, # log 출력
save_best_only = True, # bset 값만 저장
model = 'auto') # auto는 자동으로 best 찾음
stopping = EarlyStopping(monitor='val_loss', # 관찰 대상은 val_loss
patience = 5) # 5 epoch 동안 개선되지 않으면 조기종료
hist = model.fit(x_train, t_train, epochs=30, validation_split=0.2,
callbacks = [checkpoint, stopping])
Epoch 1/30
1493/1500 [============================>.] - ETA: 0s - loss: 0.3636 - accuracy: 0.8695
Epoch 1: val_loss improved from inf to 0.37178, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 4s 3ms/step - loss: 0.3636 - accuracy: 0.8695 - val_loss: 0.3718 - val_accuracy: 0.8673
Epoch 2/30
1496/1500 [============================>.] - ETA: 0s - loss: 0.3196 - accuracy: 0.8823
Epoch 2: val_loss improved from 0.37178 to 0.34138, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 4s 2ms/step - loss: 0.3195 - accuracy: 0.8824 - val_loss: 0.3414 - val_accuracy: 0.8784
Epoch 3/30
1494/1500 [============================>.] - ETA: 0s - loss: 0.3015 - accuracy: 0.8891
Epoch 3: val_loss did not improve from 0.34138
1500/1500 [==============================] - 4s 2ms/step - loss: 0.3016 - accuracy: 0.8891 - val_loss: 0.3480 - val_accuracy: 0.8781
Epoch 4/30
1494/1500 [============================>.] - ETA: 0s - loss: 0.2901 - accuracy: 0.8932
Epoch 4: val_loss did not improve from 0.34138
1500/1500 [==============================] - 4s 2ms/step - loss: 0.2902 - accuracy: 0.8932 - val_loss: 0.3503 - val_accuracy: 0.8751
Epoch 5/30
1494/1500 [============================>.] - ETA: 0s - loss: 0.2818 - accuracy: 0.8982
Epoch 5: val_loss improved from 0.34138 to 0.32908, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2816 - accuracy: 0.8983 - val_loss: 0.3291 - val_accuracy: 0.8844
Epoch 6/30
1487/1500 [============================>.] - ETA: 0s - loss: 0.2713 - accuracy: 0.9004
Epoch 6: val_loss did not improve from 0.32908
1500/1500 [==============================] - 3s 2ms/step - loss: 0.2708 - accuracy: 0.9006 - val_loss: 0.3404 - val_accuracy: 0.8804
Epoch 7/30
1482/1500 [============================>.] - ETA: 0s - loss: 0.2648 - accuracy: 0.9017
Epoch 7: val_loss did not improve from 0.32908
1500/1500 [==============================] - 4s 2ms/step - loss: 0.2646 - accuracy: 0.9018 - val_loss: 0.3413 - val_accuracy: 0.8820
Epoch 8/30
1499/1500 [============================>.] - ETA: 0s - loss: 0.2561 - accuracy: 0.9059
Epoch 8: val_loss did not improve from 0.32908
1500/1500 [==============================] - 4s 2ms/step - loss: 0.2560 - accuracy: 0.9059 - val_loss: 0.3356 - val_accuracy: 0.8832
Epoch 9/30
1480/1500 [============================>.] - ETA: 0s - loss: 0.2497 - accuracy: 0.9067
Epoch 9: val_loss did not improve from 0.32908
1500/1500 [==============================] - 3s 2ms/step - loss: 0.2499 - accuracy: 0.9067 - val_loss: 0.3783 - val_accuracy: 0.8645
Epoch 10/30
1477/1500 [============================>.] - ETA: 0s - loss: 0.2443 - accuracy: 0.9094
Epoch 10: val_loss improved from 0.32908 to 0.31827, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 4s 2ms/step - loss: 0.2449 - accuracy: 0.9095 - val_loss: 0.3183 - val_accuracy: 0.8873
Epoch 11/30
1484/1500 [============================>.] - ETA: 0s - loss: 0.2393 - accuracy: 0.9123
Epoch 11: val_loss did not improve from 0.31827
1500/1500 [==============================] - 4s 2ms/step - loss: 0.2393 - accuracy: 0.9124 - val_loss: 0.3276 - val_accuracy: 0.8832
Epoch 12/30
1497/1500 [============================>.] - ETA: 0s - loss: 0.2351 - accuracy: 0.9130
Epoch 12: val_loss did not improve from 0.31827
1500/1500 [==============================] - 3s 2ms/step - loss: 0.2350 - accuracy: 0.9130 - val_loss: 0.3241 - val_accuracy: 0.8878
Epoch 13/30
1494/1500 [============================>.] - ETA: 0s - loss: 0.2280 - accuracy: 0.9159
Epoch 13: val_loss did not improve from 0.31827
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2282 - accuracy: 0.9158 - val_loss: 0.3664 - val_accuracy: 0.8780
Epoch 14/30
1482/1500 [============================>.] - ETA: 0s - loss: 0.2272 - accuracy: 0.9171
Epoch 14: val_loss did not improve from 0.31827
1500/1500 [==============================] - 4s 3ms/step - loss: 0.2265 - accuracy: 0.9174 - val_loss: 0.3225 - val_accuracy: 0.8864
Epoch 15/30
1478/1500 [============================>.] - ETA: 0s - loss: 0.2212 - accuracy: 0.9179
Epoch 15: val_loss did not improve from 0.31827
1500/1500 [==============================] - 4s 2ms/step - loss: 0.2209 - accuracy: 0.9181 - val_loss: 0.3241 - val_accuracy: 0.8875
In [ ]:
model.evaluate(x_test, t_test)
313/313 [==============================] - 1s 2ms/step - loss: 0.3529 - accuracy: 0.8806
Out[ ]:
[0.35292068123817444, 0.8805999755859375]In [ ]:
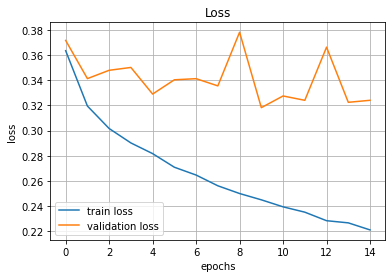
plt.title('Loss')
plt.xlabel('epochs')
plt.ylabel('loss')
plt.grid()
plt.plot(hist.history['loss'], label='train loss')
plt.plot(hist.history['val_loss'], label='validation loss')
plt.legend(loc='best')
plt.show()
In [ ]:
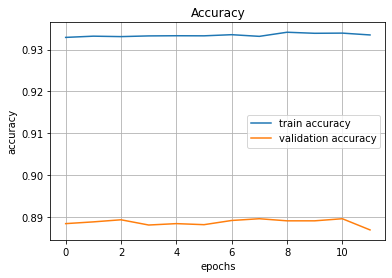
plt.title('Accuracy')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.grid()
plt.plot(hist.history['accuracy'], label='train accuracy')
plt.plot(hist.history['val_accuracy'], label='validation accuracy')
plt.legend(loc='best')
plt.show()
In [ ]:
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape = (28,28)))
model.add(tf.keras.layers.Dense(100, activation = 'relu'))
model.add(tf.keras.layers.Dense(10, activation = 'softmax'))
In [ ]:
from tensorflow.keras.optimizers import SGD
model.compile(optimizer = SGD(learning_rate = 0.1), loss = 'sparse_categoricalentropy',
metrics = ['accuracy'])
In [ ]:
reduceLR = ReduceLROnPlateau()
In [ ]:
In [ ]:
In [ ]:
In [ ]:
In [ ]:
'AI > Computer Vision' 카테고리의 다른 글
| 02_NN_MNIST_sparse_dropout_batchnormalization (0) | 2022.08.01 |
|---|---|
| 01_NN_MNIST_example_onehot (0) | 2022.08.01 |
| 00_Introduction_to_CNN (0) | 2022.08.01 |
| 04_kaggle_diabetes_data (0) | 2022.08.01 |
| 03_pandas quick review (0) | 2022.08.01 |
'AI/Computer Vision' Related Articles
more




Comments