
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
Tags
- 텐서플로우
- Deeplearning
- Python
- 데이터전처리
- 머신러닝
- resnet
- 데이터사이언스
- ComputerVision
- AI
- 케라스
- mnist
- CNN
- 빅분기실기
- 빅데이터분석기사
- 빅분기
- 파이썬
- TensorFlow
- 의학논문
- 데이터분석
- 통계
- 데이터EDA
- 데이터모델링
- 인공지능
- 딥러닝
- 데이터분석가
- 의학통계
- machinelearning
- 컴퓨터비전
- Keras
- 코딩테스트
- Today
- Total
Be Brave, Be Humble
02_NN_MNIST_sparse_dropout_batchnormalization 본문

Sparse ver
[1] MNIST Data 생성 및 확인
In [ ]:
import tensorflow as tf
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, Dropout, BatchNormalization
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
In [ ]:
(X_train, t_train), (X_test, t_test) = mnist.load_data()
print()
print('X_train.shape = ', X_train.shape, ', t_train.shape = ', t_train.shape) # (batch_size, W, H) = 데이터 수, width, height, (channel). 흑백 사진이라 채널 1이라서 생략
print('X_test.shape = ', X_test.shape, ', t_test.shape = ', t_test.shape)
# (batch_size, W, H, channel) <= 이미지는 4차원으로 표현됨
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz
11493376/11490434 [==============================] - 0s 0us/step
11501568/11490434 [==============================] - 0s 0us/step
X_train.shape = (60000, 28, 28) , t_train.shape = (60000,)
X_test.shape = (10000, 28, 28) , t_test.shape = (10000,)
In [ ]:
import matplotlib.pyplot as plt
# 25개의 이미지 출력
plt.figure(figsize = (6, 6))
for index in range(25): # 25개 출력
plt.subplot(5, 5, index + 1) # 5행 5열
plt.imshow(X_train[index], cmap = 'gray')
plt.axis('off')
plt.show()

In [ ]:
plt.imshow(X_train[9], cmap = 'gray')
plt.colorbar()
plt.show()

[2] 데이터 전처리
In [ ]:
# X_train, X_test 값 범위를 0~1 사이로 정규화
# 일반적으로 이미지는 정규화를 해야 fitting이 잘 된다고 알려져 있음!!
X_train = X_train / 255.0
X_test = X_test / 255.0
# 정규화 결과 확인
print('train max = ', X_train[0].max(), ',train min = ', X_train[0].min())
print('test max = ', X_test[0].max(), ',test min = ', X_test[0].min())
train max = 1.0 ,train min = 0.0
test max = 1.0 ,test min = 0.0
[3] 모델 구축 및 컴파일
Dropout
- rate에 지정된 비율만큼 랜덤하게 층과 층 사이 연결을 끊어서 overfitting을 방지함
- input data를 바꿀 수 없다면 output을 바꾸는 개념임. output이 바뀌면 loss입장에서는 input이 바뀐 것과 동일한 효과를 보기 때문.
In [ ]:
model = Sequential() # model 생성
model.add(Flatten(input_shape = (28, 28, 1))) # 신경망은 데이터가 1차원 벡터로 들어와야 해서 Flatten. 784 각각이 feature라고 생각하면 됨
model.add(Dense(100, activation = 'relu'))
# model.add(tf.keras.layers.Dropout(0.25)) # drop out 추가
model.add(tf.keras.layers.Dropout(0.50))
# model.add(tf.keras.layers.Dropout(0.75))
model.add(Dense(10, activation = 'softmax'))
In [ ]:
from tensorflow.keras.optimizers import SGD
model.compile(optimizer = SGD(),
loss = 'sparse_categorical_crossentropy',
metrics = ['accuracy'])
model.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_2 (Flatten) (None, 784) 0
dense_3 (Dense) (None, 100) 78500
dropout_1 (Dropout) (None, 100) 0
dense_4 (Dense) (None, 10) 1010
=================================================================
Total params: 79,510
Trainable params: 79,510
Non-trainable params: 0
_________________________________________________________________
[4] 모델 학습
Callback
In [ ]:
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
checkpoint = ModelCheckpoint(filepath = './modelcheckpoint_test.h5',
moniter = 'val_loss',
verbose = 1,
save_best_only = True,
model = 'auto')
stopping = EarlyStopping(monitor = 'val_loss',
patience = 5)
In [ ]:
hist = model.fit(X_train, t_train, epochs=50, validation_split=0.2,
callbacks = [checkpoint, stopping])
Epoch 1/50
1486/1500 [============================>.] - ETA: 0s - loss: 0.9166 - accuracy: 0.7251
Epoch 1: val_loss improved from inf to 0.42199, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 4s 2ms/step - loss: 0.9151 - accuracy: 0.7255 - val_loss: 0.4220 - val_accuracy: 0.8963
Epoch 2/50
1475/1500 [============================>.] - ETA: 0s - loss: 0.5265 - accuracy: 0.8469
Epoch 2: val_loss improved from 0.42199 to 0.32512, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 4s 2ms/step - loss: 0.5249 - accuracy: 0.8474 - val_loss: 0.3251 - val_accuracy: 0.9128
Epoch 3/50
1484/1500 [============================>.] - ETA: 0s - loss: 0.4406 - accuracy: 0.8722
Epoch 3: val_loss improved from 0.32512 to 0.28562, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.4403 - accuracy: 0.8723 - val_loss: 0.2856 - val_accuracy: 0.9223
Epoch 4/50
1478/1500 [============================>.] - ETA: 0s - loss: 0.3930 - accuracy: 0.8863
Epoch 4: val_loss improved from 0.28562 to 0.25767, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 4s 2ms/step - loss: 0.3931 - accuracy: 0.8864 - val_loss: 0.2577 - val_accuracy: 0.9283
Epoch 5/50
1500/1500 [==============================] - ETA: 0s - loss: 0.3641 - accuracy: 0.8953
Epoch 5: val_loss improved from 0.25767 to 0.24128, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 4s 2ms/step - loss: 0.3641 - accuracy: 0.8953 - val_loss: 0.2413 - val_accuracy: 0.9329
Epoch 6/50
1490/1500 [============================>.] - ETA: 0s - loss: 0.3439 - accuracy: 0.8994
Epoch 6: val_loss improved from 0.24128 to 0.22527, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.3436 - accuracy: 0.8995 - val_loss: 0.2253 - val_accuracy: 0.9367
Epoch 7/50
1482/1500 [============================>.] - ETA: 0s - loss: 0.3215 - accuracy: 0.9074
Epoch 7: val_loss improved from 0.22527 to 0.21353, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 4s 2ms/step - loss: 0.3210 - accuracy: 0.9076 - val_loss: 0.2135 - val_accuracy: 0.9404
Epoch 8/50
1477/1500 [============================>.] - ETA: 0s - loss: 0.3080 - accuracy: 0.9122
Epoch 8: val_loss improved from 0.21353 to 0.20453, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.3074 - accuracy: 0.9122 - val_loss: 0.2045 - val_accuracy: 0.9420
Epoch 9/50
1478/1500 [============================>.] - ETA: 0s - loss: 0.2959 - accuracy: 0.9142
Epoch 9: val_loss improved from 0.20453 to 0.19583, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 4s 2ms/step - loss: 0.2962 - accuracy: 0.9141 - val_loss: 0.1958 - val_accuracy: 0.9457
Epoch 10/50
1494/1500 [============================>.] - ETA: 0s - loss: 0.2831 - accuracy: 0.9192
Epoch 10: val_loss improved from 0.19583 to 0.18870, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.2834 - accuracy: 0.9192 - val_loss: 0.1887 - val_accuracy: 0.9473
Epoch 11/50
1487/1500 [============================>.] - ETA: 0s - loss: 0.2749 - accuracy: 0.9201
Epoch 11: val_loss improved from 0.18870 to 0.18248, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 4s 2ms/step - loss: 0.2745 - accuracy: 0.9202 - val_loss: 0.1825 - val_accuracy: 0.9490
Epoch 12/50
1496/1500 [============================>.] - ETA: 0s - loss: 0.2680 - accuracy: 0.9225
Epoch 12: val_loss improved from 0.18248 to 0.17760, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.2686 - accuracy: 0.9223 - val_loss: 0.1776 - val_accuracy: 0.9504
Epoch 13/50
1494/1500 [============================>.] - ETA: 0s - loss: 0.2593 - accuracy: 0.9247
Epoch 13: val_loss improved from 0.17760 to 0.17166, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.2595 - accuracy: 0.9247 - val_loss: 0.1717 - val_accuracy: 0.9522
Epoch 14/50
1497/1500 [============================>.] - ETA: 0s - loss: 0.2532 - accuracy: 0.9272
Epoch 14: val_loss improved from 0.17166 to 0.16810, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 4s 2ms/step - loss: 0.2534 - accuracy: 0.9272 - val_loss: 0.1681 - val_accuracy: 0.9534
Epoch 15/50
1484/1500 [============================>.] - ETA: 0s - loss: 0.2480 - accuracy: 0.9276
Epoch 15: val_loss improved from 0.16810 to 0.16354, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 4s 2ms/step - loss: 0.2479 - accuracy: 0.9277 - val_loss: 0.1635 - val_accuracy: 0.9542
Epoch 16/50
1500/1500 [==============================] - ETA: 0s - loss: 0.2424 - accuracy: 0.9296
Epoch 16: val_loss improved from 0.16354 to 0.16040, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.2424 - accuracy: 0.9296 - val_loss: 0.1604 - val_accuracy: 0.9559
Epoch 17/50
1478/1500 [============================>.] - ETA: 0s - loss: 0.2350 - accuracy: 0.9330
Epoch 17: val_loss improved from 0.16040 to 0.15630, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.2346 - accuracy: 0.9329 - val_loss: 0.1563 - val_accuracy: 0.9564
Epoch 18/50
1494/1500 [============================>.] - ETA: 0s - loss: 0.2337 - accuracy: 0.9331
Epoch 18: val_loss improved from 0.15630 to 0.15409, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 4s 2ms/step - loss: 0.2334 - accuracy: 0.9333 - val_loss: 0.1541 - val_accuracy: 0.9572
Epoch 19/50
1475/1500 [============================>.] - ETA: 0s - loss: 0.2265 - accuracy: 0.9346
Epoch 19: val_loss improved from 0.15409 to 0.15078, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.2268 - accuracy: 0.9346 - val_loss: 0.1508 - val_accuracy: 0.9582
Epoch 20/50
1476/1500 [============================>.] - ETA: 0s - loss: 0.2241 - accuracy: 0.9354
Epoch 20: val_loss improved from 0.15078 to 0.14764, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 4s 2ms/step - loss: 0.2237 - accuracy: 0.9354 - val_loss: 0.1476 - val_accuracy: 0.9599
Epoch 21/50
1477/1500 [============================>.] - ETA: 0s - loss: 0.2182 - accuracy: 0.9373
Epoch 21: val_loss improved from 0.14764 to 0.14514, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 4s 2ms/step - loss: 0.2182 - accuracy: 0.9373 - val_loss: 0.1451 - val_accuracy: 0.9603
Epoch 22/50
1496/1500 [============================>.] - ETA: 0s - loss: 0.2130 - accuracy: 0.9377
Epoch 22: val_loss improved from 0.14514 to 0.14297, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 4s 2ms/step - loss: 0.2129 - accuracy: 0.9377 - val_loss: 0.1430 - val_accuracy: 0.9617
Epoch 23/50
1490/1500 [============================>.] - ETA: 0s - loss: 0.2123 - accuracy: 0.9389
Epoch 23: val_loss improved from 0.14297 to 0.14178, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.2123 - accuracy: 0.9389 - val_loss: 0.1418 - val_accuracy: 0.9612
Epoch 24/50
1488/1500 [============================>.] - ETA: 0s - loss: 0.2117 - accuracy: 0.9387
Epoch 24: val_loss improved from 0.14178 to 0.13971, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.2120 - accuracy: 0.9386 - val_loss: 0.1397 - val_accuracy: 0.9618
Epoch 25/50
1494/1500 [============================>.] - ETA: 0s - loss: 0.2063 - accuracy: 0.9399
Epoch 25: val_loss improved from 0.13971 to 0.13705, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.2061 - accuracy: 0.9400 - val_loss: 0.1371 - val_accuracy: 0.9623
Epoch 26/50
1499/1500 [============================>.] - ETA: 0s - loss: 0.2026 - accuracy: 0.9408
Epoch 26: val_loss improved from 0.13705 to 0.13498, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 4s 2ms/step - loss: 0.2028 - accuracy: 0.9407 - val_loss: 0.1350 - val_accuracy: 0.9632
Epoch 27/50
1480/1500 [============================>.] - ETA: 0s - loss: 0.2012 - accuracy: 0.9405
Epoch 27: val_loss improved from 0.13498 to 0.13427, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.2007 - accuracy: 0.9406 - val_loss: 0.1343 - val_accuracy: 0.9632
Epoch 28/50
1481/1500 [============================>.] - ETA: 0s - loss: 0.2003 - accuracy: 0.9415
Epoch 28: val_loss improved from 0.13427 to 0.13238, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.2000 - accuracy: 0.9417 - val_loss: 0.1324 - val_accuracy: 0.9639
Epoch 29/50
1486/1500 [============================>.] - ETA: 0s - loss: 0.1963 - accuracy: 0.9426
Epoch 29: val_loss improved from 0.13238 to 0.13143, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 4s 2ms/step - loss: 0.1964 - accuracy: 0.9425 - val_loss: 0.1314 - val_accuracy: 0.9647
Epoch 30/50
1477/1500 [============================>.] - ETA: 0s - loss: 0.1966 - accuracy: 0.9428
Epoch 30: val_loss improved from 0.13143 to 0.13109, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.1964 - accuracy: 0.9429 - val_loss: 0.1311 - val_accuracy: 0.9638
Epoch 31/50
1481/1500 [============================>.] - ETA: 0s - loss: 0.1908 - accuracy: 0.9438
Epoch 31: val_loss improved from 0.13109 to 0.12848, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.1908 - accuracy: 0.9438 - val_loss: 0.1285 - val_accuracy: 0.9653
Epoch 32/50
1495/1500 [============================>.] - ETA: 0s - loss: 0.1912 - accuracy: 0.9440
Epoch 32: val_loss improved from 0.12848 to 0.12774, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.1910 - accuracy: 0.9441 - val_loss: 0.1277 - val_accuracy: 0.9657
Epoch 33/50
1484/1500 [============================>.] - ETA: 0s - loss: 0.1879 - accuracy: 0.9462
Epoch 33: val_loss improved from 0.12774 to 0.12684, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 4s 2ms/step - loss: 0.1883 - accuracy: 0.9460 - val_loss: 0.1268 - val_accuracy: 0.9661
Epoch 34/50
1500/1500 [==============================] - ETA: 0s - loss: 0.1870 - accuracy: 0.9454
Epoch 34: val_loss improved from 0.12684 to 0.12530, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.1870 - accuracy: 0.9454 - val_loss: 0.1253 - val_accuracy: 0.9663
Epoch 35/50
1499/1500 [============================>.] - ETA: 0s - loss: 0.1841 - accuracy: 0.9466
Epoch 35: val_loss improved from 0.12530 to 0.12445, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.1841 - accuracy: 0.9466 - val_loss: 0.1244 - val_accuracy: 0.9661
Epoch 36/50
1490/1500 [============================>.] - ETA: 0s - loss: 0.1822 - accuracy: 0.9477
Epoch 36: val_loss improved from 0.12445 to 0.12280, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 4s 2ms/step - loss: 0.1821 - accuracy: 0.9477 - val_loss: 0.1228 - val_accuracy: 0.9665
Epoch 37/50
1497/1500 [============================>.] - ETA: 0s - loss: 0.1804 - accuracy: 0.9478
Epoch 37: val_loss did not improve from 0.12280
1500/1500 [==============================] - 4s 2ms/step - loss: 0.1803 - accuracy: 0.9479 - val_loss: 0.1230 - val_accuracy: 0.9662
Epoch 38/50
1479/1500 [============================>.] - ETA: 0s - loss: 0.1793 - accuracy: 0.9475
Epoch 38: val_loss improved from 0.12280 to 0.12057, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.1796 - accuracy: 0.9474 - val_loss: 0.1206 - val_accuracy: 0.9677
Epoch 39/50
1498/1500 [============================>.] - ETA: 0s - loss: 0.1737 - accuracy: 0.9498
Epoch 39: val_loss improved from 0.12057 to 0.11929, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 4s 2ms/step - loss: 0.1736 - accuracy: 0.9499 - val_loss: 0.1193 - val_accuracy: 0.9672
Epoch 40/50
1475/1500 [============================>.] - ETA: 0s - loss: 0.1748 - accuracy: 0.9487
Epoch 40: val_loss did not improve from 0.11929
1500/1500 [==============================] - 3s 2ms/step - loss: 0.1750 - accuracy: 0.9486 - val_loss: 0.1196 - val_accuracy: 0.9677
Epoch 41/50
1494/1500 [============================>.] - ETA: 0s - loss: 0.1764 - accuracy: 0.9481
Epoch 41: val_loss improved from 0.11929 to 0.11859, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.1761 - accuracy: 0.9481 - val_loss: 0.1186 - val_accuracy: 0.9679
Epoch 42/50
1495/1500 [============================>.] - ETA: 0s - loss: 0.1733 - accuracy: 0.9497
Epoch 42: val_loss improved from 0.11859 to 0.11820, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.1734 - accuracy: 0.9497 - val_loss: 0.1182 - val_accuracy: 0.9682
Epoch 43/50
1479/1500 [============================>.] - ETA: 0s - loss: 0.1668 - accuracy: 0.9508
Epoch 43: val_loss improved from 0.11820 to 0.11723, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.1678 - accuracy: 0.9506 - val_loss: 0.1172 - val_accuracy: 0.9679
Epoch 44/50
1485/1500 [============================>.] - ETA: 0s - loss: 0.1706 - accuracy: 0.9496
Epoch 44: val_loss improved from 0.11723 to 0.11638, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.1710 - accuracy: 0.9496 - val_loss: 0.1164 - val_accuracy: 0.9683
Epoch 45/50
1476/1500 [============================>.] - ETA: 0s - loss: 0.1697 - accuracy: 0.9506
Epoch 45: val_loss improved from 0.11638 to 0.11520, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.1699 - accuracy: 0.9503 - val_loss: 0.1152 - val_accuracy: 0.9688
Epoch 46/50
1478/1500 [============================>.] - ETA: 0s - loss: 0.1630 - accuracy: 0.9528
Epoch 46: val_loss improved from 0.11520 to 0.11494, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.1625 - accuracy: 0.9530 - val_loss: 0.1149 - val_accuracy: 0.9687
Epoch 47/50
1493/1500 [============================>.] - ETA: 0s - loss: 0.1662 - accuracy: 0.9516
Epoch 47: val_loss improved from 0.11494 to 0.11356, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 4s 2ms/step - loss: 0.1665 - accuracy: 0.9515 - val_loss: 0.1136 - val_accuracy: 0.9697
Epoch 48/50
1497/1500 [============================>.] - ETA: 0s - loss: 0.1650 - accuracy: 0.9513
Epoch 48: val_loss improved from 0.11356 to 0.11250, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.1652 - accuracy: 0.9512 - val_loss: 0.1125 - val_accuracy: 0.9699
Epoch 49/50
1488/1500 [============================>.] - ETA: 0s - loss: 0.1618 - accuracy: 0.9528
Epoch 49: val_loss improved from 0.11250 to 0.11168, saving model to ./modelcheckpoint_test.h5
1500/1500 [==============================] - 3s 2ms/step - loss: 0.1616 - accuracy: 0.9528 - val_loss: 0.1117 - val_accuracy: 0.9693
Epoch 50/50
1497/1500 [============================>.] - ETA: 0s - loss: 0.1596 - accuracy: 0.9531
Epoch 50: val_loss did not improve from 0.11168
1500/1500 [==============================] - 3s 2ms/step - loss: 0.1597 - accuracy: 0.9531 - val_loss: 0.1132 - val_accuracy: 0.9690
[5] 모델 정확도 평가
In [ ]:
model.evaluate(X_test, t_test)
# 학습시킨 모델의 정확도 평가는 evaluate, 특정 값 예측은 predict
313/313 [==============================] - 1s 2ms/step - loss: 0.1077 - accuracy: 0.9679
Out[ ]:
[0.10766132920980453, 0.9678999781608582][6] 손실 및 정확도 추세
In [ ]:
plt.title('Loss Trend')
plt.xlabel('epochs')
plt.ylabel('loss')
plt.grid()
plt.plot(hist.history['loss'], label = 'training loss')
plt.plot(hist.history['val_loss'], label = 'validation loss')
plt.legend(loc = 'best')
plt.show()

In [ ]:
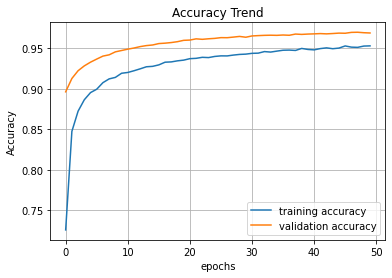
plt.title('Accuracy Trend')
plt.xlabel('epochs')
plt.ylabel('Accuracy')
plt.grid()
plt.plot(hist.history['accuracy'], label = 'training accuracy')
plt.plot(hist.history['val_accuracy'], label = 'validation accuracy')
plt.legend(loc = 'best')
plt.show()
In [ ]:
pred = model.predict(X_test)
print(pred.shape)
print(pred[:5]) # 모델이 예측한 pred[:5] 필기체 손글씨 숫자와 정답 비교
print()
print(np.argmax(pred[:5], axis = 1))
(10000, 10)
[[6.5041682e-08 1.9348308e-08 1.3496410e-05 2.3467565e-04 1.9441547e-10
3.7691967e-07 2.3707895e-12 9.9972469e-01 4.2990314e-07 2.6316073e-05]
[2.4650546e-05 8.4481966e-05 9.9972492e-01 1.0237987e-04 5.6537473e-11
1.5138073e-05 3.6306421e-05 9.1680374e-10 1.2081747e-05 1.8661548e-11]
[5.8463638e-06 9.9767345e-01 4.9475417e-04 1.4269153e-04 3.4119839e-05
8.3090301e-05 6.6303328e-05 1.2673571e-03 2.0019483e-04 3.2058098e-05]
[9.9915242e-01 2.7999320e-06 5.9972157e-05 4.9125620e-06 6.6225419e-07
1.0621274e-04 5.0336478e-04 1.1136468e-04 1.1423935e-05 4.6763991e-05]
[1.6321452e-05 3.0850302e-07 9.0365211e-05 1.7462007e-06 9.9195015e-01
5.1326708e-05 5.8665315e-05 7.7462412e-04 1.6008620e-05 7.0404960e-03]]
[7 2 1 0 4]
[+] BatchNormalization
- 데이터 평균을 0, 표준편차를 1로 분포 시킴. 높은 학습율을 사용하여 빠른 속도로 학습하면서 overfitting을 줄이는 효과가 있다고 알려져 있지만, 데이터에 따라 효과가 없는 경우도 많음
In [ ]:
model = Sequential() # model 생성
model.add(Flatten(input_shape = (28, 28, 1))) # 신경망은 데이터가 1차원 벡터로 들어와야 해서 Flatten. 784 각각이 feature라고 생각하면 됨
model.add(Dense(100, activation = 'relu'))
model.add(BatchNormalization()) # BatchNormalization() 추가
model.add(Dense(10, activation = 'softmax'))
In [ ]:
from tensorflow.keras.optimizers import SGD
model.compile(optimizer=SGD(),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.summary()
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_3 (Flatten) (None, 784) 0
dense_5 (Dense) (None, 100) 78500
batch_normalization (BatchN (None, 100) 400
ormalization)
dense_6 (Dense) (None, 10) 1010
=================================================================
Total params: 79,910
Trainable params: 79,710
Non-trainable params: 200
_________________________________________________________________
In [ ]:
hist = model.fit(X_train, t_train, epochs=50, validation_split=0.2)
Epoch 1/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.4300 - accuracy: 0.8765 - val_loss: 0.2303 - val_accuracy: 0.9373
Epoch 2/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.2317 - accuracy: 0.9340 - val_loss: 0.1733 - val_accuracy: 0.9516
Epoch 3/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.1813 - accuracy: 0.9474 - val_loss: 0.1497 - val_accuracy: 0.9583
Epoch 4/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.1534 - accuracy: 0.9571 - val_loss: 0.1320 - val_accuracy: 0.9628
Epoch 5/50
1500/1500 [==============================] - 3s 2ms/step - loss: 0.1353 - accuracy: 0.9613 - val_loss: 0.1256 - val_accuracy: 0.9654
Epoch 6/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.1220 - accuracy: 0.9659 - val_loss: 0.1181 - val_accuracy: 0.9680
Epoch 7/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.1106 - accuracy: 0.9680 - val_loss: 0.1101 - val_accuracy: 0.9694
Epoch 8/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0974 - accuracy: 0.9732 - val_loss: 0.1091 - val_accuracy: 0.9698
Epoch 9/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0894 - accuracy: 0.9755 - val_loss: 0.1043 - val_accuracy: 0.9702
Epoch 10/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0852 - accuracy: 0.9758 - val_loss: 0.1013 - val_accuracy: 0.9704
Epoch 11/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.0774 - accuracy: 0.9782 - val_loss: 0.0992 - val_accuracy: 0.9716
Epoch 12/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0724 - accuracy: 0.9797 - val_loss: 0.0965 - val_accuracy: 0.9728
Epoch 13/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0679 - accuracy: 0.9810 - val_loss: 0.0950 - val_accuracy: 0.9735
Epoch 14/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0636 - accuracy: 0.9824 - val_loss: 0.0955 - val_accuracy: 0.9724
Epoch 15/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0587 - accuracy: 0.9841 - val_loss: 0.0921 - val_accuracy: 0.9746
Epoch 16/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0552 - accuracy: 0.9848 - val_loss: 0.0927 - val_accuracy: 0.9740
Epoch 17/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0530 - accuracy: 0.9852 - val_loss: 0.0931 - val_accuracy: 0.9745
Epoch 18/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.0495 - accuracy: 0.9861 - val_loss: 0.0914 - val_accuracy: 0.9743
Epoch 19/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0463 - accuracy: 0.9878 - val_loss: 0.0900 - val_accuracy: 0.9755
Epoch 20/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0452 - accuracy: 0.9878 - val_loss: 0.0889 - val_accuracy: 0.9756
Epoch 21/50
1500/1500 [==============================] - 4s 3ms/step - loss: 0.0434 - accuracy: 0.9880 - val_loss: 0.0900 - val_accuracy: 0.9746
Epoch 22/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0411 - accuracy: 0.9887 - val_loss: 0.0890 - val_accuracy: 0.9763
Epoch 23/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0394 - accuracy: 0.9893 - val_loss: 0.0892 - val_accuracy: 0.9761
Epoch 24/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0371 - accuracy: 0.9900 - val_loss: 0.0897 - val_accuracy: 0.9752
Epoch 25/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0347 - accuracy: 0.9911 - val_loss: 0.0880 - val_accuracy: 0.9766
Epoch 26/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0333 - accuracy: 0.9915 - val_loss: 0.0911 - val_accuracy: 0.9751
Epoch 27/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0313 - accuracy: 0.9920 - val_loss: 0.0874 - val_accuracy: 0.9761
Epoch 28/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0307 - accuracy: 0.9925 - val_loss: 0.0920 - val_accuracy: 0.9745
Epoch 29/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0317 - accuracy: 0.9915 - val_loss: 0.0909 - val_accuracy: 0.9742
Epoch 30/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0297 - accuracy: 0.9919 - val_loss: 0.0908 - val_accuracy: 0.9748
Epoch 31/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0273 - accuracy: 0.9935 - val_loss: 0.0904 - val_accuracy: 0.9758
Epoch 32/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0262 - accuracy: 0.9937 - val_loss: 0.0921 - val_accuracy: 0.9752
Epoch 33/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0258 - accuracy: 0.9935 - val_loss: 0.0902 - val_accuracy: 0.9753
Epoch 34/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0237 - accuracy: 0.9944 - val_loss: 0.0898 - val_accuracy: 0.9765
Epoch 35/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0229 - accuracy: 0.9946 - val_loss: 0.0916 - val_accuracy: 0.9741
Epoch 36/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0239 - accuracy: 0.9940 - val_loss: 0.0902 - val_accuracy: 0.9745
Epoch 37/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0215 - accuracy: 0.9955 - val_loss: 0.0920 - val_accuracy: 0.9758
Epoch 38/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0206 - accuracy: 0.9951 - val_loss: 0.0913 - val_accuracy: 0.9758
Epoch 39/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0210 - accuracy: 0.9949 - val_loss: 0.0907 - val_accuracy: 0.9758
Epoch 40/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0202 - accuracy: 0.9955 - val_loss: 0.0923 - val_accuracy: 0.9759
Epoch 41/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0198 - accuracy: 0.9952 - val_loss: 0.0918 - val_accuracy: 0.9758
Epoch 42/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0188 - accuracy: 0.9956 - val_loss: 0.0905 - val_accuracy: 0.9766
Epoch 43/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0184 - accuracy: 0.9958 - val_loss: 0.0908 - val_accuracy: 0.9760
Epoch 44/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0174 - accuracy: 0.9961 - val_loss: 0.0900 - val_accuracy: 0.9766
Epoch 45/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0182 - accuracy: 0.9957 - val_loss: 0.0936 - val_accuracy: 0.9753
Epoch 46/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0162 - accuracy: 0.9967 - val_loss: 0.0912 - val_accuracy: 0.9770
Epoch 47/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0170 - accuracy: 0.9960 - val_loss: 0.0950 - val_accuracy: 0.9755
Epoch 48/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0158 - accuracy: 0.9961 - val_loss: 0.0938 - val_accuracy: 0.9768
Epoch 49/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0150 - accuracy: 0.9967 - val_loss: 0.0924 - val_accuracy: 0.9767
Epoch 50/50
1500/1500 [==============================] - 4s 2ms/step - loss: 0.0143 - accuracy: 0.9975 - val_loss: 0.0941 - val_accuracy: 0.9764
In [ ]:
# test data 이용하여 정확도 검증
model.evaluate(X_test, t_test)
313/313 [==============================] - 1s 2ms/step - loss: 0.0895 - accuracy: 0.9756
Out[ ]:
[0.08954950422048569, 0.975600004196167]In [ ]:
# 손실함수 그래프
plt.title('Loss Trend')
plt.xlabel('epochs')
plt.ylabel('loss')
plt.grid()
plt.plot(hist.history['loss'], label='training loss')
plt.plot(hist.history['val_loss'], label='validation loss')
plt.legend(loc='best')
plt.show()

In [ ]:
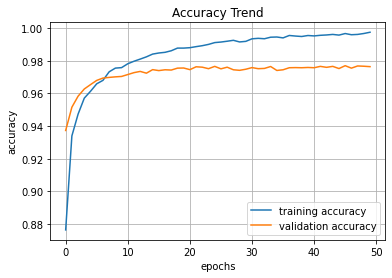
# 정확도 함수 그래프
plt.title('Accuracy Trend')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.grid()
plt.plot(hist.history['accuracy'], label='training accuracy')
plt.plot(hist.history['val_accuracy'], label='validation accuracy')
plt.legend(loc='best')
plt.show()
In [ ]:
mnist 코드
드롭아웃 dropout
배치노말라이제이션 batchnormalization
'AI > Computer Vision' 카테고리의 다른 글
| 03_Fashion_MNIST_callbacks (0) | 2022.08.01 |
|---|---|
| 01_NN_MNIST_example_onehot (0) | 2022.08.01 |
| 00_Introduction_to_CNN (0) | 2022.08.01 |
| 04_kaggle_diabetes_data (0) | 2022.08.01 |
| 03_pandas quick review (0) | 2022.08.01 |
'AI/Computer Vision' Related Articles
more




Comments