
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 의학통계
- 파이썬
- CNN
- 데이터분석
- Keras
- 컴퓨터비전
- 데이터분석가
- 인공지능
- resnet
- TensorFlow
- 딥러닝
- 데이터전처리
- 데이터사이언스
- 텐서플로우
- 케라스
- 데이터모델링
- machinelearning
- 빅데이터분석기사
- 빅분기
- Python
- AI
- Deeplearning
- 빅분기실기
- 통계
- 데이터EDA
- ComputerVision
- mnist
- 코딩테스트
- 의학논문
- 머신러닝
- Today
- Total
Be Brave, Be Humble
Python review2 본문

모듈
In [3]:
# Fibonacci numbers module
def fib(n): # write Fibonacci series up to n
a, b = 0, 1
while a < n:
print(a, end=' ')
a, b = b, a+b
def fib2(n): # return Fibonacci series up to n
result = []
a, b = 0, 1
while a < n:
result.append(a)
a, b = b, a+b
return result
if __name__ == '__main__':
print(fib2(10))
# 이 파일을 현재 폴더에 fibo.py로 저장하고
# import fibo
# from fibo import fib, fib2
# https://docs.python.org/ko/3/tutorial/modules.html[0, 1, 1, 2, 3, 5, 8]
In [ ]:
# 모듈 다시 로드
# import importlib
# importlib.reload(fibo)
관사 붙이기
In [ ]:
# version 1
# 기본 버전
# s의 첫 음절이 모음이면 an 아니면 a 붙이기
s = "apple"
s[0]
if s[0] in 'aeiouAEIOU' : #문자형도 시퀀스로 작동하기 때문에 ['a','e','i'] 이런 식으로 안 써도 됨
print("An " + s)
else:
print("A " + s)
An apple
In [ ]:
# version 2
# s의 첫 음절이 모음이면 an 아니면 a 붙이기
s = "Apple"
s[0]
if s[0] in 'aeiouAEIOU' :
print("An " + s.lower()) #단어 소문자로 출력
else:
print("A " + s.lower())
In [5]:
# version 3
#첫 음절이 알파벳이 아니면 문구 출력
s = "1 Apple"
s[0]
if s[0].lower() not in 'abcdefghijklmnopqrstuvwxyz' :
print ('첫 문자가 알파벳이 아님')
elif s[0] in 'aeiouAEIOU' :
print("An " + s.lower()) #단어 소문자로 출력
else:
print("A " + s.lower())
첫 문자가 알파벳이 아님
In [6]:
# version 5
# 파이썬 내장 함수 사용
s = "Apple"
s[0]
if not s[0].isalpha() :
print ('첫 문자가 알파벳이 아님')
elif s[0] in 'aeiouAEIOU' :
print("An " + s.lower()) #단어 소문자로 출력
else:
print("A " + s.lower())
An apple
369 함수
In [ ]:
b=386
print(type(str(b)))
print(len(str(b)))
list(str(b))
<class 'str'>
3
Out[ ]:
['3', '8', '6']In [7]:
def f369(n):
if type(n) != int or n < 0:
print("자연수만 입력하세요")
return None
a = 0
####################################
# hint: n은 숫자이므로 문자로 바꾸고... 처리
a += str(n).count('3') # 문자열로 변경하고 '3'이 몇 번 들어있는지 횟수 세기
a += str(n).count('6')
a += str(n).count('9')
####################################
if a == 0 :
return n
else :
return '짝' *a
In [9]:
####################################
# 다음코드로 결과를 확인하기
####################################
print(f369(200))
print(f369(368))
print(f369(369))
print(f369(370))
print(f369(-3))
print(f369(-3.5))
print(f369("365"))
200
짝짝
짝짝짝
짝
자연수만 입력하세요
None
자연수만 입력하세요
None
자연수만 입력하세요
None
In [11]:
####################################
# 1부터 100까지 결과를 확인하기
####################################
for i in range(1, 101):
print(i, f369(i))
1 1
2 2
3 짝
4 4
5 5
6 짝
7 7
8 8
9 짝
10 10
11 11
12 12
13 짝
14 14
15 15
16 짝
17 17
18 18
19 짝
20 20
21 21
22 22
23 짝
24 24
25 25
26 짝
27 27
28 28
29 짝
30 짝
31 짝
32 짝
33 짝짝
34 짝
35 짝
36 짝짝
37 짝
38 짝
39 짝짝
40 40
41 41
42 42
43 짝
44 44
45 45
46 짝
47 47
48 48
49 짝
50 50
51 51
52 52
53 짝
54 54
55 55
56 짝
57 57
58 58
59 짝
60 짝
61 짝
62 짝
63 짝짝
64 짝
65 짝
66 짝짝
67 짝
68 짝
69 짝짝
70 70
71 71
72 72
73 짝
74 74
75 75
76 짝
77 77
78 78
79 짝
80 80
81 81
82 82
83 짝
84 84
85 85
86 짝
87 87
88 88
89 짝
90 짝
91 짝
92 짝
93 짝짝
94 짝
95 짝
96 짝짝
97 짝
98 짝
99 짝짝
100 100
map function
In [12]:
# map(function, iterable, .. ) iterable요소를 function에 하나씩 적용
users = [{'name':'홍길동', 'age':36, 'job':'선생님'},
{'name':'김연우', 'age':18, 'job':'학생'},
{'name':'Issac Newton', 'age':5, 'job':'과학자'}]
list( map( lambda u: str(u['age'] // 10 * 10) + 's', users ) ) #user에 있는 iteration요소들을 lambda함수에 하나씩 적용.
Out[12]:
['30s', '10s', '0s']In [18]:
# 변수 여러개를 받는 함수에 적용
def element_wise_sum(x, y, z) :
return x + y + z
list(
map(
element_wise_sum,
[1,2,3], [1,3,5], [2,4,6]
)
)
Out[18]:
[4, 9, 14]In [ ]:
#위와 같음.. 쌤은 얘가 더 간편하대
for x, y, z in zip([1,2,3], [1,3,5], [2,4,6]) :
print(element_wise_sum(x,y,z) )
4
9
14
In [20]:
#최종! 가장 파이토닉한 표현
[ element_wise_sum(x,y,z) for x, y, z in zip([1,2,3], [1,3,5], [2,4,6]) ]
#[표현식 for 항목 in 순회가능객체 [if조건]]
Out[20]:
[4, 9, 14]맥주병 노래 만들기
In [ ]:
# version 1
def bottle(n):
for remainder in range(n, 0, -1) :
if remainder > 1:
s = "bottles"
else:
s = "bottle"
line1 = f"{remainder} {s} of beer on the wall, \n"
line2 = f"{remainder} {s} of beer,\n"
line3 = "Take one down, pass it around, \n"
if remainder-1 > 1:
s = "bottles"
else :
s = "bottle"
if remainder-1 == 0:
line4 = "No more bottles of beer on the wall!"
else:
line4 = f"{remainder-1} {s} of beer on the wall \n\n"
print(line1+line2+line3+line4)
bottle(3)
3 bottles of beer on the wall,
3 bottles of beer,
Take one down, pass it around,
2 bottles of beer on the wall
2 bottles of beer on the wall,
2 bottles of beer,
Take one down, pass it around,
1 bottle of beer on the wall
1 bottle of beer on the wall,
1 bottle of beer,
Take one down, pass it around,
No more bottles of beer on the wall!
In [ ]:
# version 2
def paragraph(n):
s1 = "bottles" if n > 1 else "bottle"
s2 = "bottles" if n-1 > 1 else "bottle"
last_sent = "No more bottles" if n-1 == 0 else f"{n-1} {s2}"
return '\n'.join([
f"{n} {s1} of beer on the wall,",
f"{n} {s1} of beer,",
"Take one down, pass it around,",
f"{last_sent} of beer on the wall!"
])
def bottle(n):
print(
"\n\n".join(
map(
paragraph, range(n,0,-1)
)
)
)
bottle(3)
3 bottles of beer on the wall,
3 bottles of beer,
Take one down, pass it around,
2 bottles of beer on the wall!
2 bottles of beer on the wall,
2 bottles of beer,
Take one down, pass it around,
1 bottle of beer on the wall!
1 bottle of beer on the wall,
1 bottle of beer,
Take one down, pass it around,
No more bottles of beer on the wall!
[1] *args, **kwargs
In [ ]:
###############################
# 프린트 문은 가변인자를 받을 수 있음
###############################
print(1, 2, 3, 4)
print(1, 2, 3, 4, 'aaa', 'bbb')
1 2 3 4
1 2 3 4 aaa bbb
In [37]:
##################################
# 위치 인자를 가변으로 받는 프린트 함수를 작성하기
# 함수의 인자를 *args로 지정하기
##################################
def print_args(*args):
# *args라는 인자로 모든 위치인자가 모여서 튜플로 정리됨
# 이제 print_args함수는 인자를 여러 개 지정하여 호출 할 수 있음
print("Positional argument tuple:", args)
# 위치 인자를 여러개 지정해서 함수를 호출하기
print_args(1,2,3)
Positional argument tuple: (1, 2, 3)
In [35]:
def dc_marvel(superhero, actor, movie) :
return {'superhero' : superhero, 'actor' : actor, 'movie' : movie}
print(dc_marvel('Batman', 'Ben affleck', 'Justice League')) #각 키:값 으로 출력해줌
print(dc_marvel('Ben affleck', 'Justice League', 'Batman')) #순서를 잘못 배정해줘도 얘는 못 알아들어서 그냥 순서대로 키:값 나열해벌임!!
#따라서 순서 중요!!
#매개변수의 이름을 지정하면 순서 상관없이 이름만 맞추면 됨
print(dc_marvel(actor='Ben affleck', superhero='Batman', movie='Justice League')) #키값을 직접 입력하면 순서 내맘대로 해도 됨
Positional argument tuple: (1, 2, 3)
{'superhero': 'Batman', 'actor': 'Ben affleck', 'movie': 'Justice League'}
{'superhero': 'Ben affleck', 'actor': 'Justice League', 'movie': 'Batman'}
In [36]:
##################################
# 키워드 인자를 가변으로 받는 프린트 함수를 작성하기
# 함수의 인자를 **kwargs로 지정하기
##################################
def print_kwargs(**kwargs):
# **kwargs라는 인자로 모든 키워든 인자가 모여서 사전으로 정리됨
# kwargs라는 변수명은 관행적인 것으로 다른 이름으로 바꿔 적을 수 있으나
# 거의 kwargs를 사용하는 편
print("Keyword arugument dict:", kwargs)
{'superhero': 'Batman', 'actor': 'Ben affleck', 'movie': 'Justice League'}
In [ ]:
# 키워드 인자를 여러개 지정해서 함수를 호출
print_kwargs(actor='Ben affleck', superhero='Batman')
Keyword arugument dict: {'actor': 'Ben affleck', 'superhero': 'Batman'}
In [38]:
##################################
# 위치, 키워드 인자 모드드 가변으로 받는 프린트 함수를
# print_all이라는 이름으로 작성
# hint: *args, **kwargs를 동시에 지정
##################################
def print_all(*args, **kwargs) :
print("Positional argument tuple:", args)
print("Keyword argument dict:", kwargs)
print_all(1,2,name='백현')
Positional argument tuple: (1, 2)
Keyword argument dict: {'name': '백현'}
In [48]:
# print_all()를 위치 인자, 키워드 인자를 함께 넘기면서 호출
print_all(10, 20, 'aa', 'bb', a=1, b=2, c=(123,), luck='lucky7')
# print_all(10, 20, 'aa', 'bb', a=1, b=2, c=(123,), luck='lucky7', 88)
# 위 코드는 에러! 위치 인자는 위치 인자끼리, 키워드 인자는 키워드 인자끼리 모여야 함
Positional argument tuple: (10, 20, 'aa', 'bb')
Keyword argument dict: {'a': 1, 'b': 2, 'c': (123,), 'luck': 'lucky7'}
In [ ]:
##################################
# 위치 인자와 키워드인자 위치를 뒤섞은 다음 함수를 호출
##################################
print_all(10, 20, 'aa', a=1, b=2, 'bb', c=(123)) #SyntaxError
# 위치 인자는 위치 인자끼리 키워드 인자는 키워드 인자끼리 모여 있어야 함
File "<ipython-input-7-5579f1156a62>", line 5
print_all(10, 20, 'aa', a=1, b=2, 'bb', c=(123))
^
SyntaxError: positional argument follows keyword argument
In [ ]:
##################################
# 키워드 인자를 먼저 적고 위치인자를 나중에 적은 다음 함수를 호출
##################################
print_all(a=1, b=2, c=(123), 10, 20, 'aa', 'bb')
# 순서도 위치 인자가 키워드 인자앞에 와야 함
File "<ipython-input-1-f2f3665836dd>", line 4
print_all(a=1, b=2, c=(123), 10, 20, 'aa', 'bb')
^
SyntaxError: positional argument follows keyword argument
- 위 두 셀의 실행 결과를 보면 위치인자는 반드시 키워드 인자 앞에 위치 해야 한다.
[2] 인자 풀기
In [1]:
#########################################
# 3차원 벡터의 콤포넌트를 출력하는 함수
#########################################
#함수에 전달되는 인자를 시퀀스형 그대로 전달하기
def print_vector(x, y, z):
print(f"{x}, {y}, {z}")
In [2]:
# 함수를 호출
print_vector(1,2,3)
# 튜플을 바로 넘기면 에러가 나지만
# *(...) 식으로 *를 붙여서 튜플을 풀면서 에러가 나지 않고 위치를 맞춰서 호출됨
v1 = (100, 200, 300)
print_vector(*v1)
# **로 사전을 풀어서 함수를 호출합니다.
v2 = {'x': 10, 'y':20, 'z':30}
print_vector(**v2)
1, 2, 3
100, 200, 300
10, 20, 30
In [8]:
# 패킹, 언패킹과 관련된 함수임
a, b, c = (1, 2, 3) # 언패킹
print(a)
d = 1, 2, 3 # 패킹
print(d)
def pack(x, y, z): # pack은 인자가 3개 필요한 함수
print(x, y, z)
a = (1, 2, 3)
# pack(a)
# 이렇게 세 인자를 튜플로 묶어버리면
# pack이라는 함수에서 x=(1,2,3)으로 인식하기 때문에 y,z는 인자가 없는 것으로 간주되어 에러
pack(*a) # 이 때 *를 써주면 자동으로 언패킹해줌
1
(1, 2, 3)
1 2 3
[3] 함수를 리턴: 클로저
In [10]:
########################################
# 함수를 리턴하는 함수를 작성
########################################
#변수 뿐 아니라 함수도 리턴
#목적 1)함수 내부에서 길게 반복되는 부분을 함수로 만들어 반복호출
# 2)외부 함수의 로컬 변수를 기억하는 함수를 만들어 이용
def make_func(k): #외부함수
def k_times(x): #내부에서 함수를 만들어 return
return k*x
return k_times # 리턴에는 두 번째 함수 이름
In [13]:
########################################
# 몇가지 함수를 만들어 보기
# 리턴되는 함수는
# def k_times(x):
# return 5*x
# 라는 함수가 됨.
test_5 = make_func(5) # 이렇게하면 k=5로 고정되어서 test_5라는 함수로 저장을 함.
#이제 test_5라는 함수엔 k=5로 채워진 make_fun이 들어감 ( k_times 함수의 x는 미입력 상태로 make_func이 들어감)
test_3 = make_func(3) #k=3
In [14]:
########################################
# 만들어진 함수의 호출 결과를 확인
print(test_5(10)) # x=10 대입
print(test_3(10))
50
30
[4] 제너레이터
In [15]:
########################################
# yield를 세번 정적으로 부르는 함수를 작성
def gen_123(): #제너레이터 함수
yield 1
yield 2
yield 3
In [16]:
#####################################
# 함수를 호출하고 반환값을 g에 저장
g = gen_123()
# g는 어떤 타입인가?
type(g)
Out[16]:
generatorIn [17]:
######################################
# next()를 사용하여 yield를 하나씩 실행
# next() 호출될 때 마다 gen_123()함수 내부에 yield 문이 하나씩 실행되면서
# 1, 2, 3을 순차적으로 리턴
print(next(g))
print(next(g))
print(next(g))
1
2
3
In [19]:
#####################################
# 다시 한번 next()를 실행
next(g)
# 모든 yield가 실행되었으므로 다시 g를 생성하기 전에는 에러!!!
---------------------------------------------------------------------------
StopIteration Traceback (most recent call last)
<ipython-input-19-b3953f84913f> in <module>()
1 #####################################
2 # 다시 한번 next()를 실행
----> 3 next(g)
4
5 # 모든 yield가 실행되었으므로 다시 g를 생성하기 전에는 에러!!!
StopIteration: - 미니배치 할 때 제너레이터 원리가 이용됨..
In [20]:
##############################################
# range함수를 간단히 구현하기
def my_range(first=0, last=10, step=1):
number = first
while number < last:
yield number # number를 리턴하고 잠시 멈춤
number += step # 다음 호출에서 여기부터 실행됨
In [27]:
##########################################
# 함수를 실행하여 generator객체를 받아오기
foo = my_range(0, 5)
foo
Out[27]:
<generator object my_range at 0x7f1450ac83d0>In [28]:
########################################
# 만든 객체를 for문에 테스트
for i in foo:
print(i)
0
1
2
3
4
In [29]:
####################################
# foo는 어떤 타입인가?
type(foo)
Out[29]:
generatorIn [24]:
######################################
# next()를 한번 더하면?
next(foo) #다 제너레이트 돼서 에러..
---------------------------------------------------------------------------
StopIteration Traceback (most recent call last)
<ipython-input-24-e8c8f9e5f436> in <module>()
1 ######################################
2 # next()를 한번 더하면?
----> 3 next(foo) #다 제너레이트 돼서 에러..
StopIteration: In [30]:
##########################################
# for문에서는 어떤지 테스트
for i in foo:
print(i)
# 에러를 내지 않고 아무 일도 일어나지 않는다. => 다 제너레이트 돼서...
In [31]:
#--- pytorch에서 decorator 사용 예 ---#
x = torch.tensor([1], requires_grad = True)
with torch.no_grad() :
y = x*2
y.requires_grad
@torch.no_grad()
def doubler(x):
return x * 2
z = doubler(x)
z.requires_grad
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-31-471986395758> in <module>()
1 #--- pytorch에서 decorator 사용 예 ---#
----> 2 x = torch.tensor([1], requires_grad = True)
3 with torch.no_grad() :
4 y = x*2
5 y.requires_grad
NameError: name 'torch' is not defined[5] 데코레이터
In [34]:
#########################################
# 데코레이터를 만들기
def format_hex(func): # 인자가 함수임...!!
# 클로저 기능을 사용하여 내부 함수를 리턴하는 함수를 만듦
# 이 내부함수는 format_hex가 전달받은 함수를 호출해서
# 그 반환결과에 어떤 추가 작업을 하는 함수
# 전달받은 함수의 인자를 미리 알 수 없으니 *args, **kwargs를 사용해서
# 임의의 인자를 처리하게 함
def new_func(*args, **kwargs):
ret = func(*args, **kwargs)
# 16진수로 변경, ret가 float인 경우 int로
return hex(int(ret))
return new_func # 내부 함수 리턴
In [38]:
#########################################
# 데코레이터를 함수처럼 불러서 데코레이팅된 함수를 생성
times_5_hex = format_hex(test_5) # 함수를 인자로 함!!
# test_5 = make_func(5)
# times_5는 숫자 하나를 인자로 받는 함수지만 일반적으로는 뭘 받는지는 우리가 모르기 때문에
# *args, **kewargs (가변인자) 넣어서 다 받을 수 있게 함
# 이제 new_func이 times_5_hex가 되는 것임..
In [39]:
##########################################
# 동작확인
times_5_hex(5)
# 25가 16진수로 변환됨
Out[39]:
'0x19'In [40]:
#########################################
# 데코레이터 문법을 사용하여 데코레이팅된 함수를 생성
@format_hex
def times_10(a):
return a*10
In [41]:
#########################################
# 동작확인
times_10(10)
Out[41]:
'0x64'In [42]:
########################################
# 인자를 여러개 받는 함수도 데코레이팅 될까?
@format_hex
def complicate_calc(a, b, c):
return (a*b)/c
In [44]:
####################################
# 만들어진 함수를 위치 인자로 호출
complicate_calc(10, 20, 30)
# 가변인자로 넣었기 때문에 가능
Out[44]:
'0x6'In [45]:
#####################################
# 만들어진 함수를 키워드 인자로 호출
complicate_calc(a=10, c=20, b=30)
# 가변인자로 넣었기 때문에 가능
Out[45]:
'0xf'[6] 예외처리 try except finally
In [46]:
# 다음 함수는 문법적으로 아무런 문제가 없지만.
def div(a, b):
return a/b
print(f"4/2={div(4,2)}")
print(f"0/2={div(0,2)}")
# 예기치 않은 인자에 의해 실행시간에 에러를 발생시킴
print(f"4/0={div(4,0)}") # 0으로 못 나누니까 ZeroDivisionError: division by zero
4/2=2.0
0/2=0.0
---------------------------------------------------------------------------
ZeroDivisionError Traceback (most recent call last)
<ipython-input-46-322d71ba1fb4> in <module>()
7
8 # 예기치 않은 인자에 의해 실행시간에 에러를 발생시킴
----> 9 print(f"4/0={div(4,0)}") # 0으로 못 나누니까 ZeroDivisionError: division by zero
<ipython-input-46-322d71ba1fb4> in div(a, b)
1 # 다음 함수는 문법적으로 아무런 문제가 없지만.
2 def div(a, b):
----> 3 return a/b
4
5 print(f"4/2={div(4,2)}")
ZeroDivisionError: division by zeroIn [47]:
# 0으로 나누는 경우를 대비하기 위해 if 문을 사용할 수 있음
def div2(a, b):
if b == 0 :
print('0으로 나눌 수 없습니다.')
return None
else:
return a/b
print(f"4/2={div2(4,2)}")
print(f"0/2={div2(0,2)}")
print(f"4/0={div2(4,0)}")
# 하지만 실행시간에 또 다른 예외가 발생할 수 있음
print(f"4/0={div2(4,'c')}") #나눗셈에 문자 넣었으니 error!! TypeError: unsupported operand type(s) for /: 'int' and 'str'
4/2=2.0
0/2=0.0
0으로 나눌 수 없습니다.
4/0=None
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-47-a344e324663e> in <module>()
12
13 # 하지만 실행시간에 또 다른 예외가 발생할 수 있음
---> 14 print(f"4/0={div2(4,'c')}") #나눗셈에 문자 넣었으니 error!! TypeError: unsupported operand type(s) for /: 'int' and 'str'
<ipython-input-47-a344e324663e> in div2(a, b)
5 return None
6 else:
----> 7 return a/b
8
9 print(f"4/2={div2(4,2)}")
TypeError: unsupported operand type(s) for /: 'int' and 'str'In [48]:
def div3(a, b):
r = None
# 일단 실행하고
try:
r = a/b
# 예상 가능한 예외에 대해서 적절히 처리
except ZeroDivisionError as err : #예측 가능한 에러 설정
print(err)
except TypeError as err : #예측 가능한 에러 설정
print(err)
except Exception as err : #예측 불가능한 에러
print('처리되지 않은 에러 발생')
print(err)
# 예상치 못한 예외에 대해서 한꺼번에 최소한의 처리를 함
# 최종적으로 무조건 실행되는 부분을 여기 코딩
# 예외 처리 후 정리해야하는 부분이나 정상 실행되었을 때
# 처리해야할 코드 등을 쓸 수 있음
finally : # finally는 필수는 아님
if r != None:
return r
else:
print("예외가 발생되어 계산을 마치지 못함")
print(f"4/2={div3(4,2)}")
print(f"0/2={div3(0,2)}")
print(f"4/0={div3(4,0)}")
print(f"4/0={div3(4,'c')}")
4/2=2.0
0/2=0.0
division by zero
예외가 발생되어 계산을 마치지 못함
4/0=None
unsupported operand type(s) for /: 'int' and 'str'
예외가 발생되어 계산을 마치지 못함
4/0=None
[7] 클래스 상속과 super()
In [49]:
#############################################
# 클래스는 정보와 기능을 덩어리 하나로 묶은 것으로
# 이 클래스에는 이름, 키, 몸무게 정보와
# 이름을 출력하는 기능, 달리기 속도를 키와 몸무게로 계산하는 기능을 가지고 있음
class Person: # class 안에는 함수도 있고, 변수도 있고...
def __init__(self, n, h,w) : # __init__는 person을 부르면 자동으로 생성됨
self.name = n # 클래스 안에만 존재하는 변수
self.height = h
self.weight = w
def who_are_you(self) :
print(self.name)
def speed(self) :
return f"{(self.height / self.weight) * 5}km/h"
In [50]:
#############################################
# 클래스를 상속하고 함수가 가려지는 상황을 실험
# 보통 사람 Person을 상속받아 SuperPerson을 만듦
# SuperPerson은 당연히 Person의 속성을 모두 가지고 있게 됨
class SuperPerson(Person):
def __init__(self, n, h, w, power):
super().__init__(n, h, w)
self.power = power
def speed(self): #Person의 스피드와 이름은 같지만 수식이 다름
return f"{(self.height / self.weight) * self.power}km/h"
In [51]:
##########################################
# 사람과 수퍼사람을 만들고
p = Person('man', 180, 75) # p라는 객체가 만들어지는 게 class
p2 = Person('man2', 170, 95)
p.who_are_you()
p2.who_are_you()
sp = SuperPerson('superman', 180, 75, 100)
man
man2
In [52]:
##########################################
# 둘의 스피드가 다르게 계산되는지 확인
# 같은 함수를 호출하지만 객체 종류에 따라 다른 함수가 호출됨
p.speed(), sp.speed()
Out[52]:
('12.0km/h', '240.0km/h')In [53]:
############################################
# 수퍼사람에게 who_are_you라고 물어볼 수 있는지? => 상속 받았기 때문에 가능~
sp.who_are_you()
superman
In [54]:
###########################################
# 수퍼사람은 자신을 위장해야 해서 항상 빨리달리면 안됨
# 평소 그냥 사람인척 할 수 있는가?
super(SuperPerson, sp).speed() # super(class이름, 객체이름)
# super라는 함수를 사용하면 가려졌던 부모의 객체를 리턴할 수 있음!!!
Out[54]:
'12.0km/h'[8] 특수 메서드 __len__, __getitem__
In [55]:
###################################
# __len__ 메서드를 가지는 데이터셋 클래스를 만듦
# 딥러닝을 코딩한다고 가정. 수 많은 데이터를 D에 저장하고
# (D는 주로 리스트나 넘파이 어레이)
# 외부요청에 따라 적당히 데이터를 반환하는 클래스를 만들 수 있음.
class MyData(): # MyData -> obj
def __init__(self, D):
self.D = D # self.D엔 데이터가 오백만개 들어있음. D는 [1,2,3]을 갖는 list
def __len__(self) : # len을 쓸 때 자동으로 호출되는 함수..
return len(self.D)
# len([1,2,3]) sequence 넣으면 길이를 알려주는 함수인데,
# len(obj) obj는 길이가 1이지만 그 안에 데이터 오백만개 => 이 오백만개를 세어줌
In [57]:
# mnist 데이터로 테스트 해보기.
# 우선 데이터를 저장할 어레이를 만들기 위해 넘파이를 임포트
# 이후 mnist 데이터를 로드하기 위해 판다스라는 라이브러리를 임포트
# 그리고 그림을 약간 그려야 하기 때문에 그림 그리는 라이브러리도 임포트
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# mnist 데이터를 읽어오기
# 이후 이 셀에 코드에 대해서는 이해가 가지 않아도 아직 신경쓰지 말고 주석을 읽으면서 진행
mnist = pd.read_csv("sample_data/mnist_train_small.csv", header=None)
# # X에는 숫자 그림이, y에는 그 숫자에 해당하는 숫자값이 들어가게 됨
X = mnist.iloc[:,1:].to_numpy() # DF를 넘파이로 바꿔서 X에 집어넣음
y = mnist.iloc[:,0].to_numpy()
# # 임의로 X에서 숫자 그림 열개를 추출
print(X.shape, y.shape) # (20000, 784), (20000,)
idx = np.random.choice(X.shape[0], 10)
samples = X[idx]
samples2 = samples.reshape(10, 28, 28).transpose(1,0,2).reshape(28,-1)\
.reshape(28,1,-1).reshape(28,-1,140).transpose(1,0,2).reshape(-1,140)
print(samples.shape) # (10, 784)
# # 적당히 열개를 그림을 그리면
fig = plt.figure(figsize=(10,5))
ax = plt.axes()
ax.imshow(samples2, cmap='binary')
plt.show()
(20000, 784) (20000,)
(10, 784)
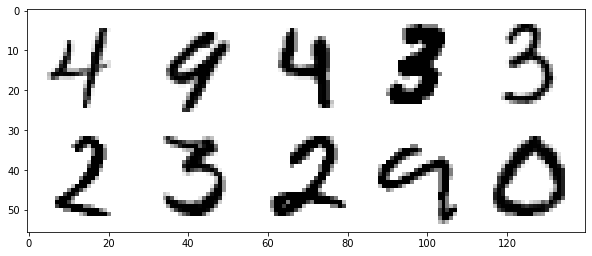
In [58]:
mnist
Out[58]:
0123456789...77577677777877978078178278378401234...1999519996199971999819999
| 6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
20000 rows × 785 columns
In [69]:
########################################
# 데이터 셋으로 이미지 다섯개를 초기화
D = MyData(X[:5]) # MyData 클래스에 넣어줌
F = X[:7]
print(D)
print()
print(F)
<__main__.MyData object at 0x7f145092aad0>
[[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
...
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 0]]
In [60]:
########################################
# __len__()함수를 직접 호출
D.__len__()
Out[60]:
5In [74]:
#######################################
# len()이라는 함수에게 D를 넘겨주기
print(len(D))
print(len(F))
# 이렇게 해서 데이터 클래스에 데이터가 몇개가 들어 있는지 간편히 알 수 있음
## ... F는 그냥 알 수 있는데 굳이..?
5
7
In [75]:
#######################################
# D안에 객체(이미지)를 인덱싱할 수 있나요? => 안 돼!!!!!!!!!!!!
D[2]
# F[2] # F는 됨..
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-75-5226858e03eb> in <module>()
1 #######################################
2 # D안에 객체(이미지)를 인덱싱할 수 있나요? => 안 돼!!!!!!!!!!!!
----> 3 D[2]
4 # F[2] # F는 됨..
TypeError: 'MyData' object is not subscriptableIn [76]:
########################################
# 인덱싱까지 되는 객체를 만들어 보기
class MyData():
def __init__(self, D):
self.D = D
def __len__(self):
return len(self.D)
def __getitem__(self, i): # i= 인덱싱할 i번째 아이템을 의미
return self.D[i]
In [81]:
X
X[:5] #5행까지 출력
Out[81]:
array([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]])In [78]:
########################################
# 데이터 셋으로 이미지 다섯개를 초기화
D = MyData(X[:5])
In [79]:
#######################################
# len(D)를 실행해서 길이를 확인
len(D)
Out[79]:
5In [ ]:
########################################
# 이제 인덱싱이 되나요?
D[4] # 안에 숫자 0~4까지 가능. 왜냐면 넘파이 어레이(X)를 5까지 잘랐으니까
In [85]:
sample = D[4]
fig = plt.figure()
ax = plt.axes()
ax.imshow(sample.reshape(28,28), cmap='binary')
plt.show()
''' F는 굳이 클래스나 특수메서드 쓰지 않아도 되는데 쓰는 이유가 뭘까 '''

[9] 특수 메서드 __call__
In [2]:
################################################
# callable한 객체를 만들기 위한 기본 객체임
# 이 객체는 실제로 아무일도 하지 않고
# __call__함수를 자식에게 전달하는 역할만 함
class A(object):
def __init__(self):
pass
def __call__(self, *args, **kwargs): # 여러개의 가변인자를 전달 받아서 forward 함수에 전달
self.forward(*args, **kwargs)
def forward(self, *args, **kwargs):
pass
###### 추상적인 클래스의 뼈대만 만들고
In [3]:
################################################
# 실제 forward 함수의 구체적 클래스는 여기서 만든다
# 왜냐면 이렇게 상속해서 클래스를 만들면 프로그래머가 여러명이어도 클래스의 스펙은 동일...
class B(A): # A를 상속시킴
def __init__(self, inc, out):
super(B, self).__init__()
self.inc = inc
self.out = out
def forward(self, s, i):
print(s * self.inc, i * self.out)
In [4]:
################################################
# 객체를 만들고 타입을 확인
b = B(2,3)
print(type(b))
print(type(b.forward))
<class '__main__.B'>
<class 'method'>
In [5]:
################################################
# 부모 클래스가 __call__함수를 구현해 놓았기 때문에
# 객체를 마치 함수 호출하듯이 호출할 수 있음
# b.forward('aaaaa', 1)와 같은 표현
b('aaaaa', 1)
b.forward('aaaaa', 1)
aaaaaaaaaa 3
aaaaaaaaaa 3
In [6]:
callable(b)
Out[6]:
True[10] 콘텍스트 매니저 with
In [7]:
#########################################
# 일반적인 파일 오픈 방식을 테스트 하기
# 파일 읽고 쓰기 https://wikidocs.net/16077
f = open('foo.txt', 'w')
f.write('no with')
# f를 가지고 어떤 작업을 열심히 하고
f.close() # 마지막에 닫아야 함
# <- 왼쪽 파일에 들어가면 foo.txt가 생기는 것을 확인할 수 있음
In [8]:
########################################
# 콘텍스트 매니저를 사용하여 같은 작업을 해보기
with open('bar.txt', 'w') as f:
f.write('with')
# 어떤 작업을 열심히 하고...
# 이 블록은 문맥을 유지하는 범위
# 블록을 벗어나면(문맥을 벗어나면) 자동으로 파일이 닫힘
# <- 왼쪽 파일에 들어가면 bar.txt가 생기는 것을 확인할 수 있음
pythonic coding
In [11]:
#######################################
# 약수를 구하는 코드 1
def divisor1(N):
i = 1
d = []
while i <= N:
if N % i == 0: # 나머지 0이면 추가
d.append(i)
i += 1
return d
In [12]:
divisor1(60)
Out[12]:
[1, 2, 3, 4, 5, 6, 10, 12, 15, 20, 30, 60]In [13]:
#######################################
# 약수를 구하는 코드 2
def divisor2(N):
d = []
for i in range(1, N+1):
if N % i == 0:
d.append(i)
return(d)
In [15]:
divisor2(80)
Out[15]:
[1, 2, 4, 5, 8, 10, 16, 20, 40, 80]In [16]:
#######################################
# 약수를 구하는 코드 3
def divisor3(N):
return [i for i in range(1, N+1) if N % i == 0 ]
In [17]:
divisor3(120)
Out[17]:
[1, 2, 3, 4, 5, 6, 8, 10, 12, 15, 20, 24, 30, 40, 60, 120]In [24]:
#######################################
# 약수를 구하는 코드 4
# def로 정식 함수를 만들지 않고 람다를 사용함
divisor4 = lambda N: [ i for i in range(1, N+1) if N % i == 0 ]
In [25]:
divisor4(60)
Out[25]:
[1, 2, 3, 4, 5, 6, 10, 12, 15, 20, 30, 60]2차원 리스트 연습
In [33]:
[j+1 for j in range(4)]
Out[33]:
[1, 2, 3, 4]In [36]:
# 2차원 리스트 연습
L = []
for i in range(3):
I = []
for j in range(4):
I.append(j+i)
L.append(I)
L
Out[36]:
[[0, 1, 2, 3], [1, 2, 3, 4], [2, 3, 4, 5]]softmax
In [55]:
import math
class Softmax():
def __init__(self):
self.v = [] # 함숫값을 저장할 리스트
self.deriv = [] # 미분계수를 저장할 리스트
def forward(self, x): # x: 요소 K개인 list
self.K = len(x) # x 안에 들어있는 숫자의 개수
self.denom = 0.0 # softmax 함수값을 계산하기 위한 분모
self.numer = [] # softmax 함수값을 계산하기 위한 분자 K개 저장위한 리스트
####################################################
#
# 1. 함숫값 구성을 위해 분자와 분모를 계산
for x_i in x:
ex_i = math.exp(x_i)
self.denom += ex_i # 분모
self.numer.append(ex_i) # 분자
# 2. 계산된 분자 분모를 이용해서 함숫값을 계산
for numer in self.numer:
self.v.append(numer / self.denom)
####################################################
def __getitem__(self, i):
try:
return self.v[i]
except IndexError as e:
print(e)
def backward(self):
####################################################
#
# 1. K개 행을 순환하면서
for i in range(self.K):
# 각 행을 저장할 빈 리스트를 만들고
L = []
# 2. 다시 K개 열을 순환하면서
for j in range(self.K):
if i == j :
L.append(self.v[i]*(1-self.v[i])) # softmax 미분계수 대각행렬
else :
L.append(-self.v[i]*self.v[j]) # softmax미분계수 비대각행렬
# 3. 계산이 완료된 한 행을 self.deriv에 추가하고
# 나머지 K-1개 행에 대해서도 같은 작업을 반복
self.deriv.append(L)
####################################################
In [51]:
import torch
In [56]:
# forward check
# 위 클래스가 바르게 코딩되었다면
# 이 셀의 실행 값은 매우 작게 출력되어야 함. 대략 +-1.0e-8 정도
score = [6.3, 1.4, 3.2, 2.9]
s = Softmax()
s.forward(score) # score를 포워드 시켜서 함수값 계산
s2 = torch.tensor(s.v) # 계산된 함수값 리스트인 v를 tensor 타입으로 만들기
# torch.tensor는 어떤 data를 tensor로 copy해주는 함수
# import numpy as np
# tt = np.array(s.v)
# print(tt)
x = torch.tensor(score, dtype=torch.float, requires_grad=True)
st = torch.nn.functional.softmax(x, dim=0)
print(st)
print(s2)
(st - s2).sum().item()
tensor([0.9209, 0.0069, 0.0415, 0.0307], grad_fn=<SoftmaxBackward0>)
tensor([0.9209, 0.0069, 0.0415, 0.0307])
Out[56]:
1.1920928955078125e-07In [57]:
# backward check
# 위 클래스가 바르게 코딩되었다면
# 이 셀의 실행 값은 매우 작게 출력되어야 함. 대략 +-1.0e-8 정도
s.backward()
x = torch.tensor(score, dtype=torch.float, requires_grad=True)
st = torch.nn.functional.softmax(x, dim=0)
J1 = torch.stack([ torch.autograd.grad(st[i], x, retain_graph=True)[0]
for i in range(len(score)) ], dim=1)
J2 = torch.tensor(s.deriv)
print(J1)
print(J2)
(J1 - J2).sum().item()
tensor([[ 0.0728, -0.0063, -0.0382, -0.0283],
[-0.0063, 0.0068, -0.0003, -0.0002],
[-0.0382, -0.0003, 0.0398, -0.0013],
[-0.0283, -0.0002, -0.0013, 0.0298]])
tensor([[ 0.0728, -0.0063, -0.0382, -0.0283],
[-0.0063, 0.0068, -0.0003, -0.0002],
[-0.0382, -0.0003, 0.0398, -0.0013],
[-0.0283, -0.0002, -0.0013, 0.0298]])
Out[57]:
-9.764335118234158e-08In [ ]:
'AI > Intermediate' 카테고리의 다른 글
| 02_decision_tree (0) | 2022.08.04 |
|---|---|
| 01_linear_and_logistic (0) | 2022.07.26 |
| 00_intro_sklearn (0) | 2022.07.25 |
| 03_numpy (0) | 2022.07.25 |
| <Read me> Describe: (0) | 2022.07.22 |
'AI/Intermediate' Related Articles
more



Comments